Crossbeam的无锁并发Channel解析
crossbeam是一个提供并发编程的工具库,实现了诸如原子Cell、工作窃取双端队列、分段队列、
多生产者多消费者Channel等无锁并发数据结构,在运行时、调度器、线程同步等领域应用广泛。
虽然Rust标准库中也提供了用于线程同步的mpsc::channel,不过内置的channel实现算法和crossbeam不同,也不支持多个消费者。
标准库的mpsc::channel使用的是
Non-intrusive MPSC node-based queue
算法,这个算法在多生产者单消费者的模型下性能非常高,下图对比了Rust内置channel、crossbeam的分段队列、Scala MSQ、Java ConcurrentLinkedQueue在
多生产者单消费者模型下的基准测试:
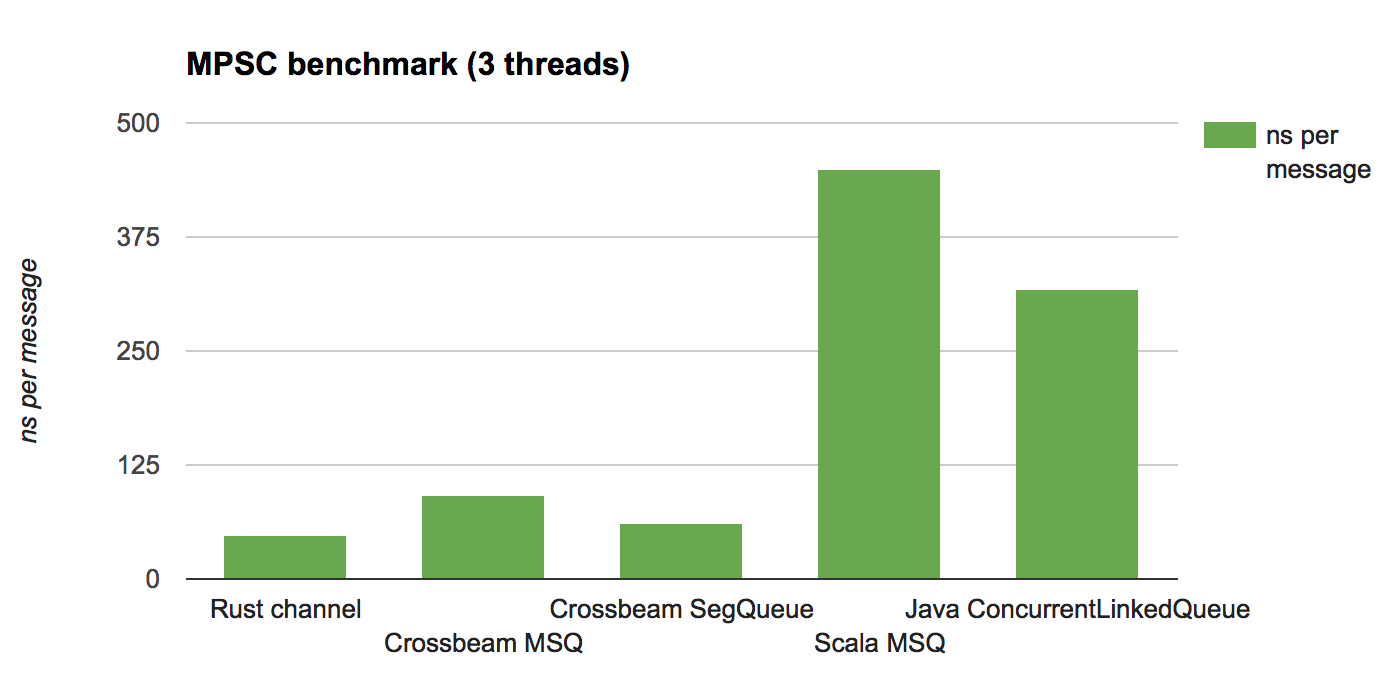
可以发现Rust内置channel和crossbeam的分段队列在基准测试中的表现要明显优于Scala/Java的Jvm平台,原因在于Jvm平台使用了垃圾收集器(GC)。 在多生产者单消费者模型下,生产的速率大于消费,这会导致数据积压越来越多,进而Jvm在GC时需要扫描的对象也愈来愈多,花费在GC上的时间也就越多。
而crossbeam在实现无锁并发结构时,采用了基于代的内存回收方式1,这种算法的内存管理开销和数据对象的数量无关,只和线程的数量相关,因此在 以上模型中可以表现出更好的一致性和可预测性。不过Rust中的所有权系统已经保证了内存安全,那为什么还需要做额外的内存回收呢?这个问题的关键点 就在要实现无锁并发结构。如果使用标准库中的Arc自然就不会有内存回收的问题,但对Arc进行读写是需要锁的。关于基于代的内存回收也是一个比较大的话题, 这篇文章不会深入讨论。
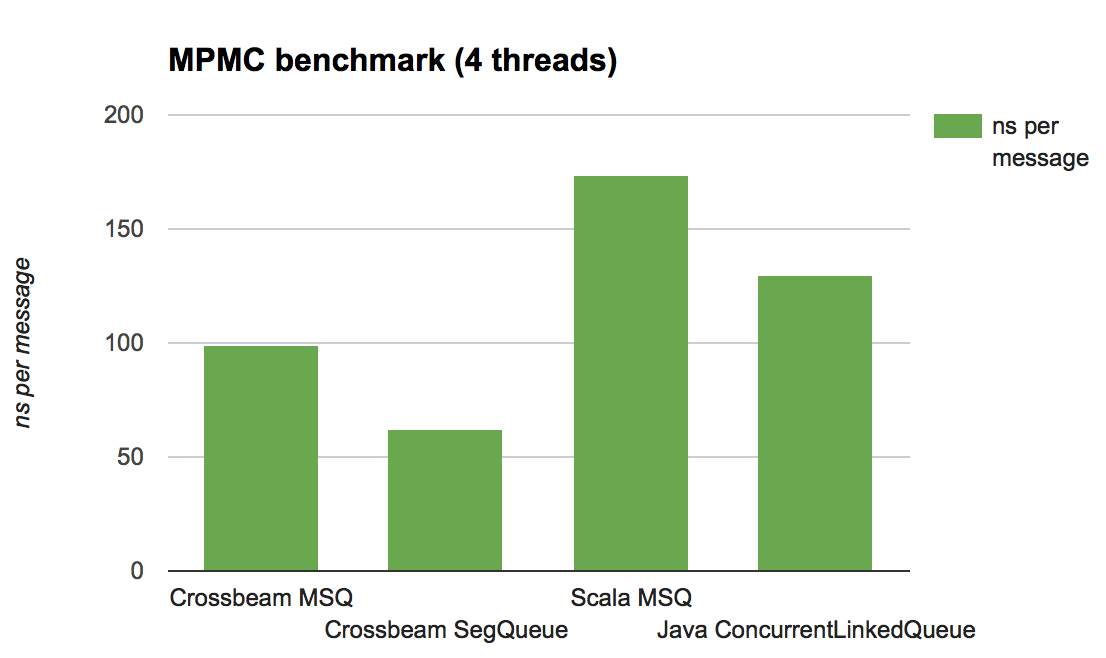
而在多生产者多消费者的模型中,crossbeam同样具有相当的性能优势,以下是多生产者多消费者模型下的基准测试:
无锁并发Channel
[0] ---->[0]
[1] | [1]
[2] | [2]
[3] | [3]
. | .
. | .
[N]---- [N]----
在crossbeam的无锁并发Channel结构中,最核心的算法思想也是分段,每次需要分配额外的空间时,一次分配一个块(Block),一个Block内包含了多个Slot(槽)。 而在进行读写数据时,先通过原子操作获取Slot的操作权限,并发操作不需要等数据完整地写入或读取,将竞争的临界区尽可能地缩小。
/// Unbounded channel implemented as a linked list.
///
/// Each message sent into the channel is assigned a sequence number, i.e. an index. Indices are
/// represented as numbers of type `usize` and wrap on overflow.
///
/// Consecutive messages are grouped into blocks in order to put less pressure on the allocator and
/// improve cache efficiency.
pub struct Channel<T> {
/// The head of the channel.
head: CachePadded<Position<T>>,
/// The tail of the channel.
tail: CachePadded<Position<T>>,
/// Receivers waiting while the channel is empty and not disconnected.
receivers: SyncWaker,
/// Indicates that dropping a `Channel<T>` may drop messages of type `T`.
_marker: PhantomData<T>,
}
Channel最外层就是由Block组成的链表。
可以发现表头和表尾都使用了CachePadded这个结构,这个结构和高速缓存的缓存行(cache line)优化有关。CachePadded这个结构的类型大小等于 cache line的整数倍,同时足够容纳类型T,这样就可以避免2个对象同处于一个cache line内,带来的好处就是修改某个对象不会使其他对象所在的线程cache line失效。
而receivers字段保存了当channel为空时阻塞的消费者线程,当写入新数据后,可以从中有条件地唤醒消费者线程,底层实现基于 条件变量。
/// A position in a channel.
#[derive(Debug)]
struct Position<T> {
/// The index in the channel.
index: AtomicUsize,
/// The block in the linked list.
block: AtomicPtr<Block<T>>,
}
Position结构中index保存了表头或表尾在整个Channel中的索引位置,block则是指向块的原子指针。
NOTE: 需要注意的是index需要去除低位的元信息后才是真正的索引位置。
// Each block covers one "lap" of indices.
const LAP: usize = 32;
// The maximum number of messages a block can hold.
const BLOCK_CAP: usize = LAP - 1;
// ..
/// A block in a linked list.
///
/// Each block in the list can hold up to `BLOCK_CAP` messages.
struct Block<T> {
/// The next block in the linked list.
next: AtomicPtr<Block<T>>,
/// Slots for messages.
slots: [Slot<T>; BLOCK_CAP],
}
在Block结构中next保存了下一个Block的原子指针,slots则是当前Block的所有槽,每个槽可以保存一个数据,可以看到目前一个Block内有31个槽。
NOTE: 之所以BLOCK_CAP的值取2的幂次减1,是因为在通过index取模计算在Block中的偏移量时,可以利用位运算优化。
/// A slot in a block.
struct Slot<T> {
/// The message.
msg: UnsafeCell<MaybeUninit<T>>,
/// The state of the slot.
state: AtomicUsize,
}
在Slot结构中msg用于保存数据,state则是目前这个Slot的状态,这个状态也是非常关键的,基于这个状态才能实现最小化竞争临界区。
/// Sends a message into the channel.
pub fn send(&self, msg: T, _deadline: Option<Instant>) -> Result<(), SendTimeoutError<T>> {
let token = &mut Token::default();
assert!(self.start_send(token));
unsafe {
self.write(token, msg)
.map_err(SendTimeoutError::Disconnected)
}
}
当需要send一个数据时,大体上分为3步:
- 获取下一个槽的操作权限
- 写入数据
- 设置已写入状态
而只有第一步是会有竞争的,只要完成了第一步,其他线程的send操作就可以马上进行。
/// The token type for the list flavor.
#[derive(Debug)]
pub struct ListToken {
/// The block of slots.
block: *const u8,
/// The offset into the block.
offset: usize,
}
其中的Token主要是为第一步和第二步提供桥梁,获取到槽的操作权限后,相关信息会通过Token传递给write方法去写数据。
在start_send方法中:
// Calculate the offset of the index into the block.
let offset = (tail >> SHIFT) % LAP;
偏移量offset从index去除低位元信息后取模计算而来。
// If we reached the end of the block, wait until the next one is installed.
if offset == BLOCK_CAP {
backoff.snooze();
tail = self.tail.index.load(Ordering::Acquire);
block = self.tail.block.load(Ordering::Acquire);
continue;
}
当offset等于Block的容量时,说明其他线程正在创建新的Block,因此这里会利用backoff来等待:
#[inline]
pub fn snooze(&self) {
if self.step.get() <= SPIN_LIMIT {
for _ in 0..1 << self.step.get() {
atomic::spin_loop_hint();
}
} else {
#[cfg(not(feature = "std"))]
for _ in 0..1 << self.step.get() {
atomic::spin_loop_hint();
}
#[cfg(feature = "std")]
::std::thread::yield_now();
}
if self.step.get() <= YIELD_LIMIT {
self.step.set(self.step.get() + 1);
}
}
snooze方法的实现部分借鉴了Mutex,在前面一定周期内进行自旋,并且自旋的次数会依次递增,直到YIELD_LIMIT,当超过一定周期后,就让出CPU。
NOTE: 在no_std环境下会一直使用自旋方式来等待。
Pslydhh在 Move the tail pointer forward instead of only spinning #88 中提出了一种其他线程协助链接下一个Block的做法,不过这种做法在竞争的情况下会有多个next block被创建,而只有一个被链接上, 这会导致额外的内存分配和回收开销。
// If we're going to have to install the next block, allocate it in advance in order to
// make the wait for other threads as short as possible.
if offset + 1 == BLOCK_CAP && next_block.is_none() {
next_block = Some(Box::new(Block::<T>::new()));
}
当offset + 1等于BLOCK_CAP,并且next_block为空时,此时需要创建下一个Block。(如果next_block不为空,说明之前创建过一次,但是链接时被抢先了)
// If this is the first message to be sent into the channel, we need to allocate the
// first block and install it.
if block.is_null() {
let new = Box::into_raw(Box::new(Block::<T>::new()));
if self
.tail
.block
.compare_and_swap(block, new, Ordering::Release)
== block
{
self.head.block.store(new, Ordering::Release);
block = new;
} else {
next_block = unsafe { Some(Box::from_raw(new)) };
tail = self.tail.index.load(Ordering::Acquire);
block = self.tail.block.load(Ordering::Acquire);
continue;
}
}
而当block为空时,说明是第一次向Channel发送消息,因此需要先创建第一个Block,这里可以看到Channel的初始化是惰性的,从Channel的构造方法也可以看到这一点:
/// Creates a new unbounded channel.
pub fn new() -> Self {
Channel {
head: CachePadded::new(Position {
block: AtomicPtr::new(ptr::null_mut()),
index: AtomicUsize::new(0),
}),
tail: CachePadded::new(Position {
block: AtomicPtr::new(ptr::null_mut()),
index: AtomicUsize::new(0),
}),
receivers: SyncWaker::new(),
_marker: PhantomData,
}
}
let new_tail = tail + (1 << SHIFT);
// Try advancing the tail forward.
match self.tail.index.compare_exchange_weak(
tail,
new_tail,
Ordering::SeqCst,
Ordering::Acquire,
) {
Ok(_) => unsafe {
// If we've reached the end of the block, install the next one.
if offset + 1 == BLOCK_CAP {
let next_block = Box::into_raw(next_block.unwrap());
self.tail.block.store(next_block, Ordering::Release);
self.tail.index.fetch_add(1 << SHIFT, Ordering::Release);
(*block).next.store(next_block, Ordering::Release);
}
token.list.block = block as *const u8;
token.list.offset = offset;
return true;
},
Err(t) => {
tail = t;
block = self.tail.block.load(Ordering::Acquire);
backoff.spin();
}
}
随后将index增加1,原子替换当前的index。注意到这里替换使用的是compare_exchange_weak方法,这是因为此时的代码本身处于一个循环中,这在部分硬件平台上
会带来更好的性能,如果使用compare_exchange,内部本身还有一个更复杂的循环用于屏蔽虚假失败,而这里我们并不需要区分虚假失败,相关的内容可以查阅
手册和维基百科。
当成功替换了index后,如果是新创建了Block则需要将这个Block链接到之前的尾端,而这时临界区已经完成,其他线程的操作可以进行下去, 最后修改Token的block和offset信息。
/// Writes a message into the channel.
pub unsafe fn write(&self, token: &mut Token, msg: T) -> Result<(), T> {
// If there is no slot, the channel is disconnected.
if token.list.block.is_null() {
return Err(msg);
}
// Write the message into the slot.
let block = token.list.block as *mut Block<T>;
let offset = token.list.offset;
let slot = (*block).slots.get_unchecked(offset);
slot.msg.get().write(MaybeUninit::new(msg));
slot.state.fetch_or(WRITE, Ordering::Release);
// Wake a sleeping receiver.
self.receivers.notify();
Ok(())
}
而write方法就比较简单了,写入数据,设置已写入状态,最后通知被阻塞的消费者线程。
/// Receives a message from the channel.
pub fn recv(&self, deadline: Option<Instant>) -> Result<T, RecvTimeoutError> {
let token = &mut Token::default();
loop {
// Try receiving a message several times.
let backoff = Backoff::new();
loop {
if self.start_recv(token) {
unsafe {
return self.read(token).map_err(|_| RecvTimeoutError::Disconnected);
}
}
if backoff.is_completed() {
break;
} else {
backoff.snooze();
}
}
if let Some(d) = deadline {
if Instant::now() >= d {
return Err(RecvTimeoutError::Timeout);
}
}
// Prepare for blocking until a sender wakes us up.
Context::with(|cx| {
let oper = Operation::hook(token);
self.receivers.register(oper, cx);
// Has the channel become ready just now?
if !self.is_empty() || self.is_disconnected() {
let _ = cx.try_select(Selected::Aborted);
}
// Block the current thread.
let sel = cx.wait_until(deadline);
match sel {
Selected::Waiting => unreachable!(),
Selected::Aborted | Selected::Disconnected => {
self.receivers.unregister(oper).unwrap();
// If the channel was disconnected, we still have to check for remaining
// messages.
}
Selected::Operation(_) => {}
}
});
}
}
recv数据时,过程其实类似:
- 获取下一个槽的操作权限
- 等待槽的已写入状态
- 读取数据
当Channel为空时,采取的策略是自旋、让出CPU、睡眠线程,这样的策略在高并发实践中也非常常见。
在start_recv方法中:
if new_head & MARK_BIT == 0 {
atomic::fence(Ordering::SeqCst);
let tail = self.tail.index.load(Ordering::Relaxed);
// If the tail equals the head, that means the channel is empty.
if head >> SHIFT == tail >> SHIFT {
// If the channel is disconnected...
if tail & MARK_BIT != 0 {
// ...then receive an error.
token.list.block = ptr::null();
return true;
} else {
// Otherwise, the receive operation is not ready.
return false;
}
}
// If head and tail are not in the same block, set `MARK_BIT` in head.
if (head >> SHIFT) / LAP != (tail >> SHIFT) / LAP {
new_head |= MARK_BIT;
}
}
head的MARK_BIT标记为0时,当前Block是最后一个Block,如果head与tail的index相同,则说明Channel为空。 tail的MARK_BIT标记不为0时,说明Channel已disconnected(生产者数量为0),不会再有新消息,此时抛出一个错误。 由于处于并发环境下,当此时的head和tail不处于同一个Block时,还需要设置head的MARK_BIT标记。
// The block can be null here only if the first message is being sent into the channel.
// In that case, just wait until it gets initialized.
if block.is_null() {
backoff.snooze();
head = self.head.index.load(Ordering::Acquire);
block = self.head.block.load(Ordering::Acquire);
continue;
}
当block为空时,说明第一条消息正在创建Block,这里就进行等待。
// Try moving the head index forward.
match self.head.index.compare_exchange_weak(
head,
new_head,
Ordering::SeqCst,
Ordering::Acquire,
) {
Ok(_) => unsafe {
// If we've reached the end of the block, move to the next one.
if offset + 1 == BLOCK_CAP {
let next = (*block).wait_next();
let mut next_index = (new_head & !MARK_BIT).wrapping_add(1 << SHIFT);
if !(*next).next.load(Ordering::Relaxed).is_null() {
next_index |= MARK_BIT;
}
self.head.block.store(next, Ordering::Release);
self.head.index.store(next_index, Ordering::Release);
}
token.list.block = block as *const u8;
token.list.offset = offset;
return true;
},
Err(h) => {
head = h;
block = self.head.block.load(Ordering::Acquire);
backoff.spin();
}
}
然后替换head,成功替换后,如果已到达当前Block的末端,则移动到下一个Block。同样,如果下一个Block正在创建,则需要等待,同时MARK_BIT也需要做相应设置。
/// Reads a message from the channel.
pub unsafe fn read(&self, token: &mut Token) -> Result<T, ()> {
if token.list.block.is_null() {
// The channel is disconnected.
return Err(());
}
// Read the message.
let block = token.list.block as *mut Block<T>;
let offset = token.list.offset;
let slot = (*block).slots.get_unchecked(offset);
slot.wait_write();
let msg = slot.msg.get().read().assume_init();
// Destroy the block if we've reached the end, or if another thread wanted to destroy but
// couldn't because we were busy reading from the slot.
if offset + 1 == BLOCK_CAP {
Block::destroy(block, 0);
} else if slot.state.fetch_or(READ, Ordering::AcqRel) & DESTROY != 0 {
Block::destroy(block, offset + 1);
}
Ok(msg)
}
在read方法中,如果对应的Slot正在写入,则需要等待其写入完成。而如果已到达当前Block的末端,则需要销毁这个Block。
不过由于处于并发环境,当获取到Slot的操作权限后,其他线程的操作已经可以进行下去,那么就会出现上一个Block的Slot还在读取过程中的情况,这时候Slot的DESTROY位 会被设置。这种情况下,读取完成的线程需要负责Block的销毁工作。
/// Sets the `DESTROY` bit in slots starting from `start` and destroys the block.
unsafe fn destroy(this: *mut Block<T>, start: usize) {
// It is not necessary to set the `DESTROY` bit in the last slot because that slot has
// begun destruction of the block.
for i in start..BLOCK_CAP - 1 {
let slot = (*this).slots.get_unchecked(i);
// Mark the `DESTROY` bit if a thread is still using the slot.
if slot.state.load(Ordering::Acquire) & READ == 0
&& slot.state.fetch_or(DESTROY, Ordering::AcqRel) & READ == 0
{
// If a thread is still using the slot, it will continue destruction of the block.
return;
}
}
// No thread is using the block, now it is safe to destroy it.
drop(Box::from_raw(this));
}
从destroy方法的实现看,在销毁前需要先设置DESTROY位,如果某个Slot还在读取过程中,则跳出。直到所有Slot都不在被使用后,执行销毁。
创建和销毁Channel
以上内容是无锁并发Channel的最核心部分:如何使发送和接收消息的并发临界区最小化。不过由于crossbeam的Channel是多生产者多消费者模型,在生产者或消费者 不再存在时,还需要执行清理、销毁Channel操作。
当生产者或消费者一方不再存在时,我们称为disconnected;只有当生产者和消费者都不再存在时,才会完全销毁Channel。
而crossbeam是通过Counter这个结构来记录生产者和消费者数量的:
/// Reference counter internals.
struct Counter<C> {
/// The number of senders associated with the channel.
senders: AtomicUsize,
/// The number of receivers associated with the channel.
receivers: AtomicUsize,
/// Set to `true` if the last sender or the last receiver reference deallocates the channel.
destroy: AtomicBool,
/// The internal channel.
chan: C,
}
/// Wraps a channel into the reference counter.
pub fn new<C>(chan: C) -> (Sender<C>, Receiver<C>) {
let counter = Box::into_raw(Box::new(Counter {
senders: AtomicUsize::new(1),
receivers: AtomicUsize::new(1),
destroy: AtomicBool::new(false),
chan,
}));
let s = Sender { counter };
let r = Receiver { counter };
(s, r)
}
从构造方法中也能看到,Sender和Receiver共享了一个Counter的裸指针。
impl<C> Sender<C> {
/// Acquires another sender reference.
pub fn acquire(&self) -> Sender<C> {
let count = self.counter().senders.fetch_add(1, Ordering::Relaxed);
// Cloning senders and calling `mem::forget` on the clones could potentially overflow the
// counter. It's very difficult to recover sensibly from such degenerate scenarios so we
// just abort when the count becomes very large.
if count > isize::MAX as usize {
process::abort();
}
Sender {
counter: self.counter,
}
}
}
impl<C> Receiver<C> {
/// Acquires another receiver reference.
pub fn acquire(&self) -> Receiver<C> {
let count = self.counter().receivers.fetch_add(1, Ordering::Relaxed);
// Cloning receivers and calling `mem::forget` on the clones could potentially overflow the
// counter. It's very difficult to recover sensibly from such degenerate scenarios so we
// just abort when the count becomes very large.
if count > isize::MAX as usize {
process::abort();
}
Receiver {
counter: self.counter,
}
}
}
Sender和Receiver的acquire方法分别用于增加生产者和消费者,实现方法则是通过增加原子计数。
impl<C> Sender<C> {
/// Releases the sender reference.
///
/// Function `disconnect` will be called if this is the last sender reference.
pub unsafe fn release<F: FnOnce(&C) -> bool>(&self, disconnect: F) {
if self.counter().senders.fetch_sub(1, Ordering::AcqRel) == 1 {
disconnect(&self.counter().chan);
if self.counter().destroy.swap(true, Ordering::AcqRel) {
drop(Box::from_raw(self.counter));
}
}
}
}
impl<C> Receiver<C> {
/// Releases the receiver reference.
///
/// Function `disconnect` will be called if this is the last receiver reference.
pub unsafe fn release<F: FnOnce(&C) -> bool>(&self, disconnect: F) {
if self.counter().receivers.fetch_sub(1, Ordering::AcqRel) == 1 {
disconnect(&self.counter().chan);
if self.counter().destroy.swap(true, Ordering::AcqRel) {
drop(Box::from_raw(self.counter));
}
}
}
}
release方法分别用于释放生产者和消费者,并且当一方的计数归0时,需要执行disconnect方法用于唤醒所有处于等待中的消费者线程和设置disconneted位标记,
这样当已经被disconnected标记后的生产者和消费者再进行操作时就会产生对应的错误。
当生产者和消费者都设置过destroy字段后,销毁Counter并间接析构Channel:
impl<T> Drop for Channel<T> {
fn drop(&mut self) {
let mut head = self.head.index.load(Ordering::Relaxed);
let mut tail = self.tail.index.load(Ordering::Relaxed);
let mut block = self.head.block.load(Ordering::Relaxed);
// Erase the lower bits.
head &= !((1 << SHIFT) - 1);
tail &= !((1 << SHIFT) - 1);
unsafe {
// Drop all messages between head and tail and deallocate the heap-allocated blocks.
while head != tail {
let offset = (head >> SHIFT) % LAP;
if offset < BLOCK_CAP {
// Drop the message in the slot.
let slot = (*block).slots.get_unchecked(offset);
let p = &mut *slot.msg.get();
p.as_mut_ptr().drop_in_place();
} else {
// Deallocate the block and move to the next one.
let next = (*block).next.load(Ordering::Relaxed);
drop(Box::from_raw(block));
block = next;
}
head = head.wrapping_add(1 << SHIFT);
}
// Deallocate the last remaining block.
if !block.is_null() {
drop(Box::from_raw(block));
}
}
}
}
Channel的析构方法会依次销毁每个Block中的每个Slot。
小结
无锁并发Channel作为crossbeam中的并发数据结构之一,在多任务系统上提供了足够好的伸缩性,实现方式也非常精妙,我们可以在诸多Rust并发应用中看到它的身影。
参考资料
- Lock-freedom without garbage collection
- Rust PR:Mostly-LF -> Lock-Free
- https://en.cppreference.com/w/cpp/atomic/atomic/compare_exchange
- Understanding std::atomic::compare_exchange_weak() in C++11
- Load-link/store-conditional
-
Epoch-based memory reclamation - Practical lock-freedom ↩︎